
https://zyros.dev/ausdevs_conversations/
TLDR
I split the conversations into chunks, then asked Gemini whether the chunks should be merged. Then I asked Gemini to describe the conversation three times (what’s the sentiment, topic, and technical topic). This was vectorised using Gemini’s embedding model, and then I did dimensionality reduction so that it’s viewable on a 2D plot. See FAQs at the bottom if you have any questions.
Background
AusDevs 2.0.0 is an Australian discord server that mostly has students or recent graduates using it. Their wiki page is here, https://ausdevs.com/, and it’s mostly supported by smish. I search this pretty often, and I’m pretty interested in natural language things so figured this would be a nice project.
Data
You can figure out how I collected this data. I’m not going to get into it.
Feature Engineering
Now that I have my data, I need to go parse it. Discord data is pretty needlessly verbose for my purposes.
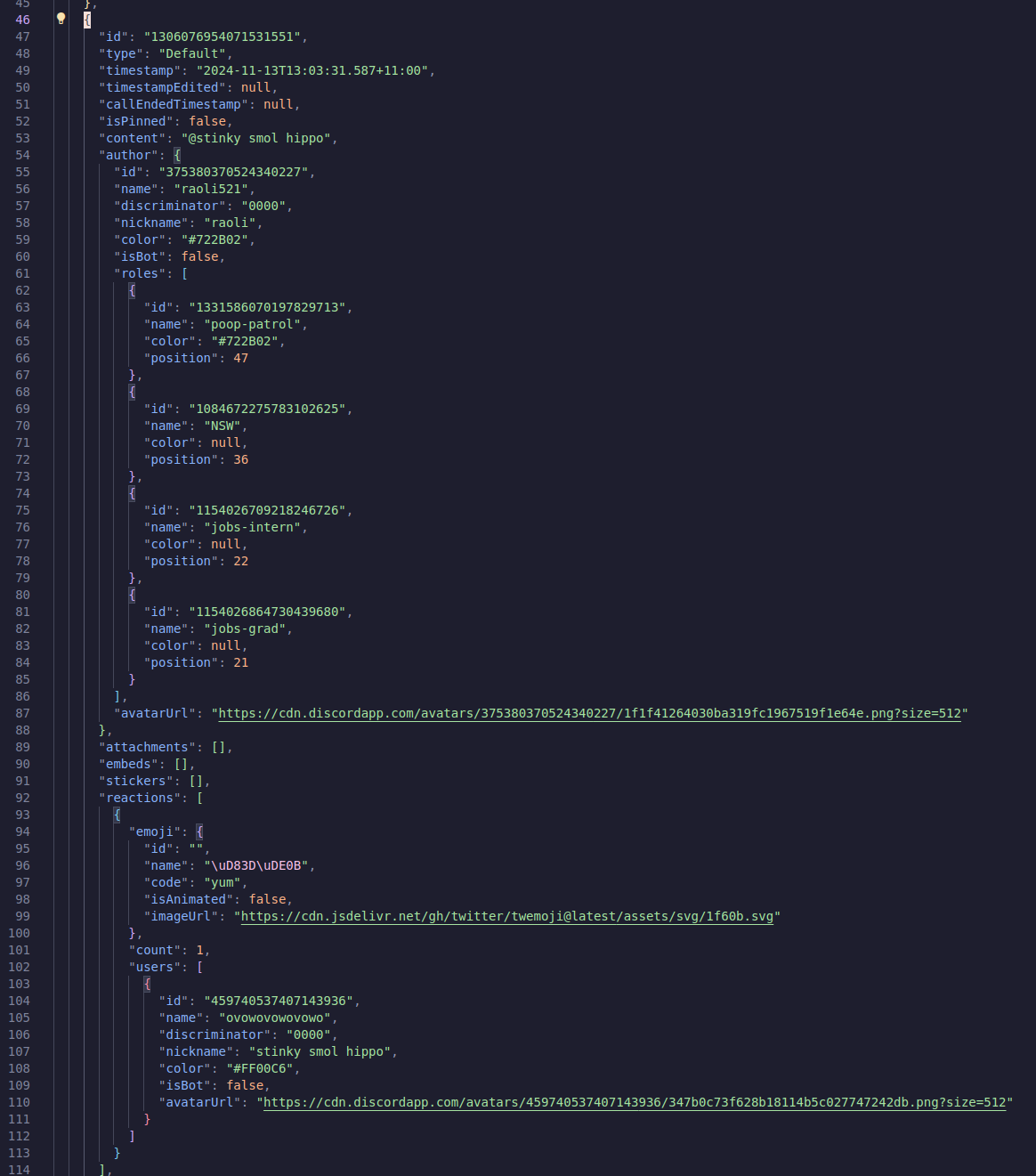
This message above is 126 lines of JSON meta data. Contains stuff like peoples roles, what emojis they used, what their username is, what the message’s unique ID is in discord’s database, so on and so on.
My feature engineering has three core classes. The chunker, the describer and the embedder. For chunking I first do a semantic chunk (maximum of 50 messages, split if there’s over 2 hours between two messages), then inside of my chunker I’ll ask the LLM whether or not I should merge these two together
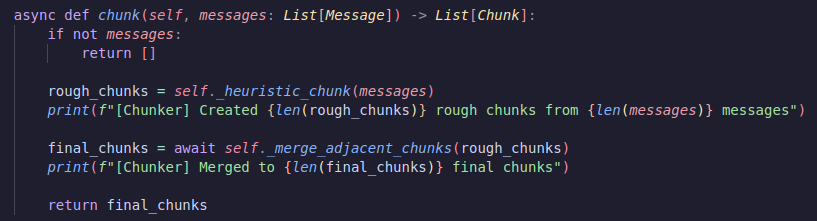
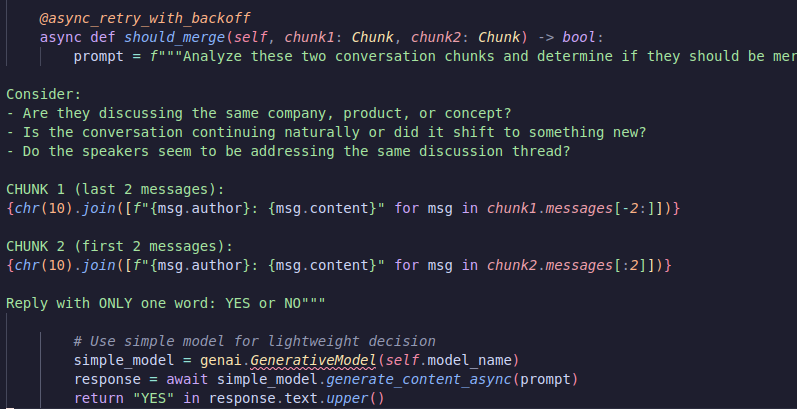
Now we have chunks! Let’s go describe
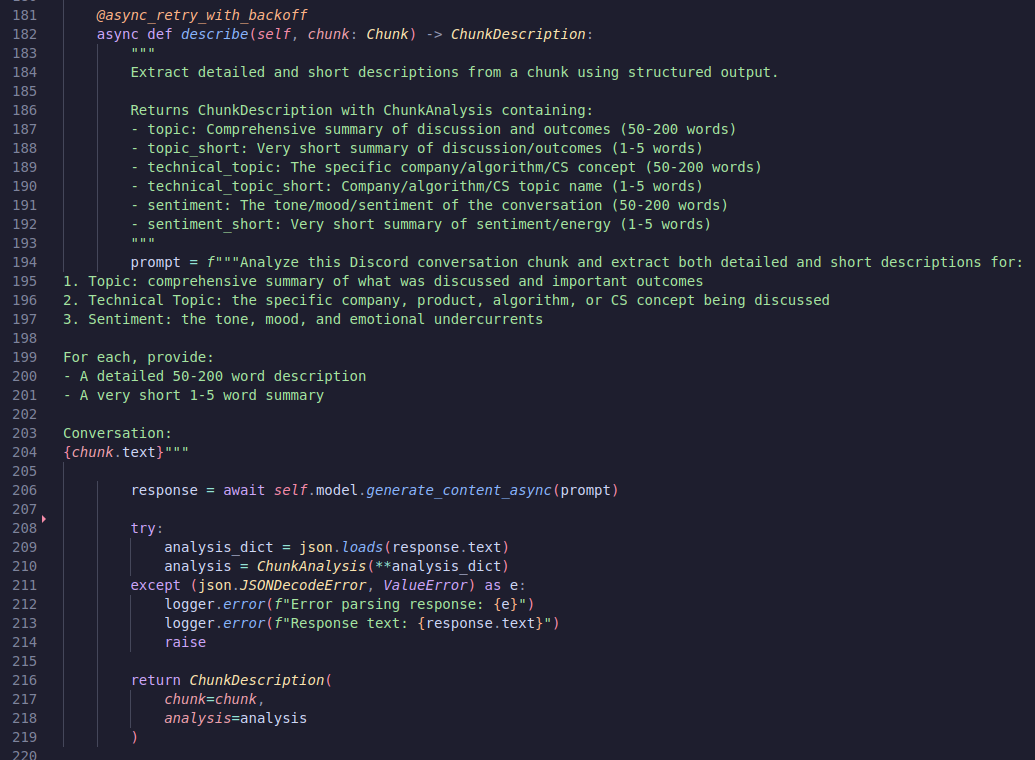
This writes a description of the conversation with the topic, technical topic, and sentiment. My original idea here was that you’d be able to search a specific technical topic (like operating systems, or maybe the name of a company). However, when applied to everything it comes out a bit weirdly.
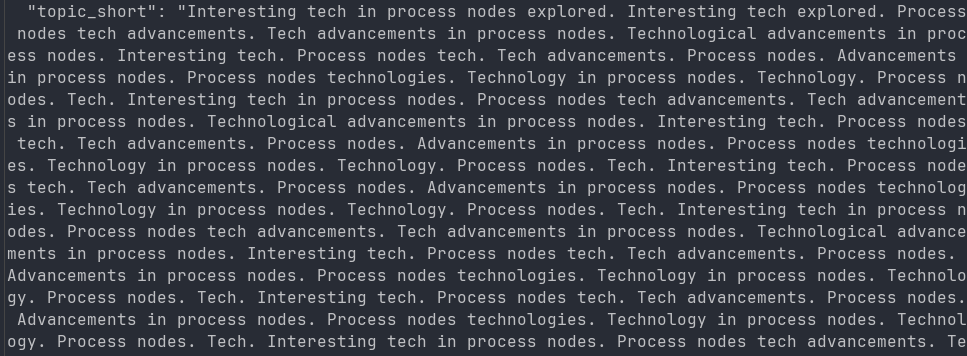
The first time I ran it, I was using Gemini 2.5 Flash Lite. It immediately imploded like this. It seems there’s an internal bug that grants it the benefit of insanity (repetitive tokens). I didn’t worry too much and rolled down to the 2.0 Lite endpoint instead.
At first I ran this with 32 threads, then I realised that’s far too slow. We have something like 1 million messages, which is probably going to be 10 million tokens. I swapped over to asyncio, and made it spin up to 4,000 concurrent requests and-
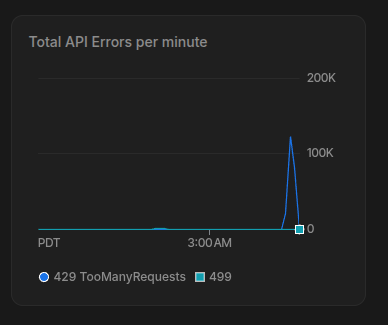
Oops. I just hit the endpoint with 125k requests. I miscalculated. I was kind of amazed that I made a DDOSing tool that slammed out 125,000 requests in a couple of seconds, but anyways.
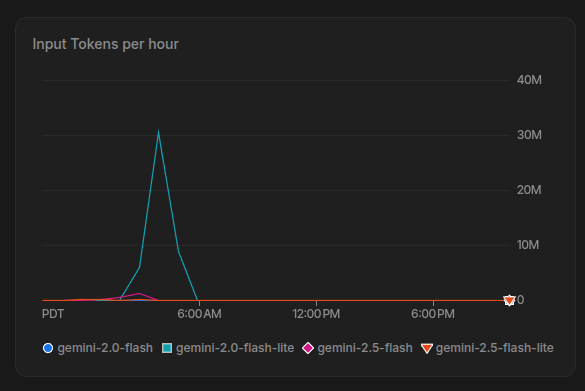
It ran for about an hour describing the entire server. Still quite long, even on the 4,000 requests per minute limit I have with gemini 2.0 flash lite.
Next up, embeddings! So, if you aren’t familiar, embeddings are very long lists of numbers that describe your information. With LLMs, they usually turn your natural language into an embedding representation at some point. We can use the Gemini API to get these embeddings, then we’ll be able to do some cool stuff. Nothing too exciting to get them. Just calling the API.
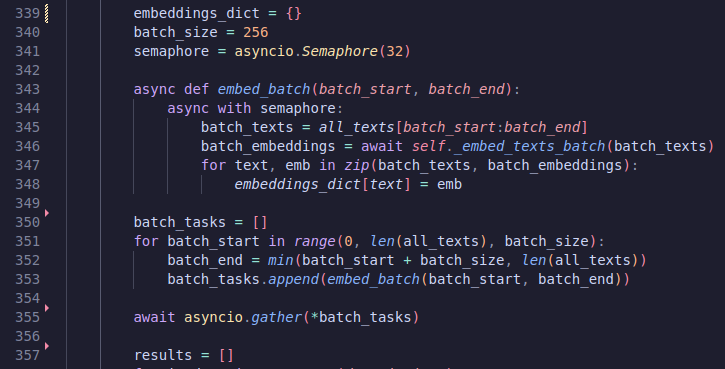
That’s the end of feature engineering, we dump all of this into JSON!
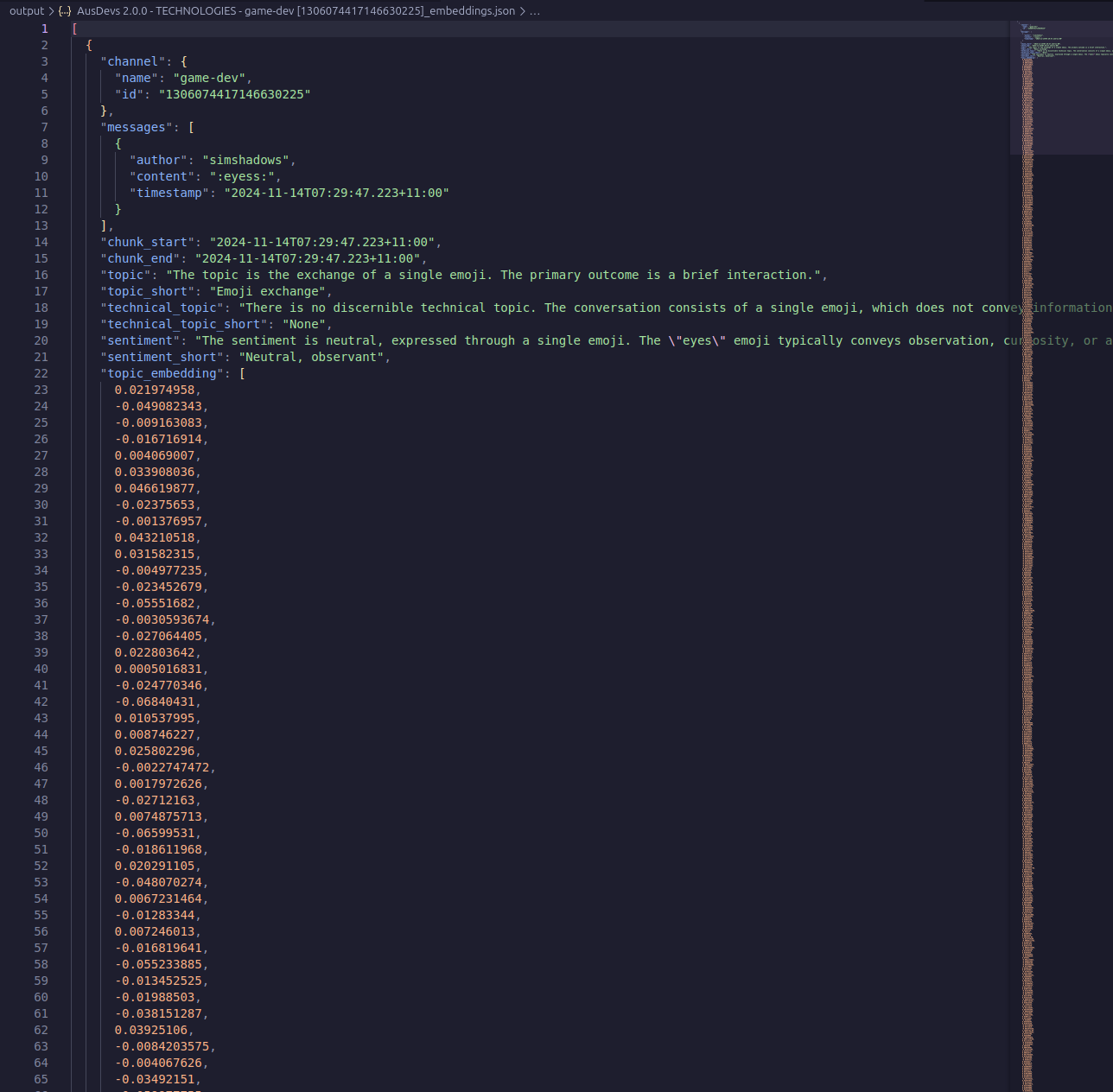
We’ll do dimensionality reduction in the next step.
Visualisation
I went through a number of visualisation libraries. The issue is that we have 40,000 points, and I want clicking to work. I tried out Gradio, but that immediately collapsed. So I swapped to streamlit, and that couldn’t support clicking! I did some investigation, then found streamlit-echarts, but that was also just old!
Great. So, I decided to go to raw TypeScript and Apache Echarts. It seems like Apache Echarts is always the winner when it comes to these things.
If you aren’t familiar, dimensionality reduction is a way to reduce the dimensions (as the name suggests!) of a vector. We have 768 dimensions for individual vectors (topic, technical topic, and sentiment), and on the combined one we have 2304 dimensions! To graph this, we need to lower this into two dimensional space, then we can graph it and show it in a way we can comprehend. This obviously loses a lot of the information, but it’s good enough for our entertainment.
Next, we need to compute the clusters and dimensionality reduction. Weirdly enough, the dimensionality reduction almost instantly worked across UMAP, PCA and PACMAP. There are a lot of other algorithms, but this is enough for different points of view. However, clustering was struggling on my CPU. With DBSCAN, it completely fell over so I swapped to KMeans, which also fell over due to RAM (25GB+). This is quite a lot of data. My combined vector is 2,304 float32s → 9 kilobytes per conversation → 300 megabytes for everything. Not insane, but a lot for a CPU to do a clustering algorithm on. So I swapped over to my GPU, which did the entire thing almost instantly.
The rest of the work is just wrangling the frontend together and deploying it, which is quite boring. So that’s it!
FAQs
- “Which user is the most…”
- Firstly, this is chunks of chats. So… its a group of people, not individual people. Also, I can’t be bothered doing the work.
- “Can I have the data?”
- I can’t be bothered uploading it somewhere; this is something I quickly slapped together for fun
- “Can you update the dataset?”
- Nah, I can’t be bothered.
- “When was this data collected?”
- Dunno, I forgot
- “How did you collect this data?”
- You can figure that out
- “The website is down!” (it currently isn’t)
- Thanks for letting me know. I might fix it this month.